- Published on
Introduction to Neural Networks
- Author

- Name
- Marco Lagos
- @marcoalagosjr
Introduction
In our nervous system, we have neurons, connected by axons and dendrites. The connecting regions are called synapses. And when a stimuli occurs, these neurons fire and the strength of the synaptic regions changes. This is our process of learning - artificial neural networks imitate this process.
General Overview
The computational units neurons are connected to one another through weights. Each input to a neuron is scaled with a weight, which affects the function computed at that unit. A neural network is a collection of neurons connected by weights, propagating the input through the network to compute the output. Learning occurs by changing the weights between neurons.
Consider a dataset . Each training instance is fed into the neural network so that it can make predictions about the output label. Depending on how well the neural network did, the weights are adjusted. By changing the weights, we hope to make better predictions in the future. Eventually, over many iterations, we would like to reach a point where the neural network, trained on the training data, is able to make accurate predictions on unseen test data. This is called generalization.
Single-layer Neural Network
This is the simplest neural network. It has input layer (not counted) and output node. Consider a training instance of the form , where each contains features, and is an observed binary value. The input layer contains nodes representing the features with edges of weight connecting the input nodes to the output node. In addition, there is often a bias term (the invariant part of the prediction) included. The bias term is a constant value that is added to the linear function. The bias term is represented by a node, called the bias neuron with a constant value of 1, and an edge of weight connecting it to the output node.
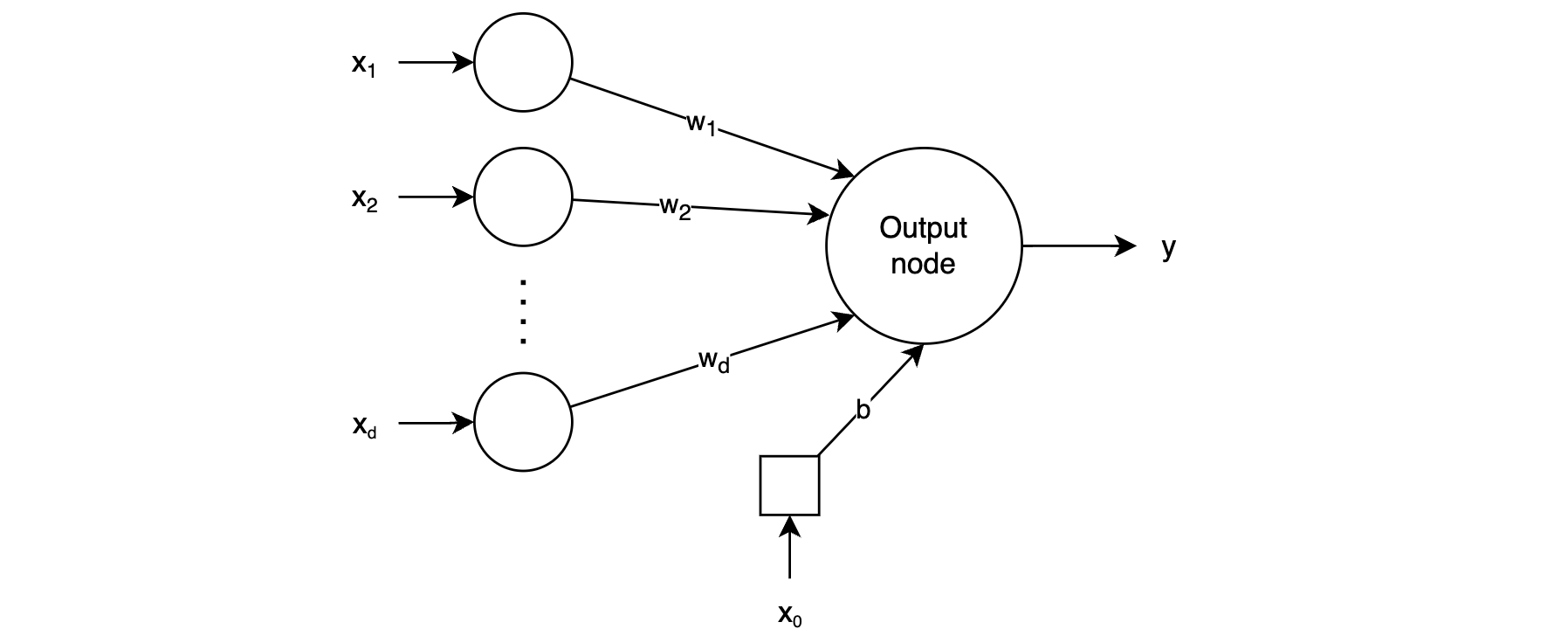
At the output node, the linear function is . The output of the network is the sign of the linear function (here corresponds to the training instance index and corresponds to the feature index):
The error can then be calculated as:
Loss function
The loss function measures how well the model is performing based on the training data. In general, we would like to minimize misclassifications or loss. For binary classification with outputs in the set , the cross-entropy loss is:
Where is the predicted probability of the positive class (i.e., ).
Our goal would then be to minimize this loss function:
To minimize this function, we can use the first derivative or its gradient to find/approach the minimum.
Gradient Descent
Gradient descent is an iterative optimization algorithm used to find the values of the weights that minimize the loss function . The general idea is to compute the gradient of the loss function with respect to each weight, and then adjust the weights in the direction of the negative gradient. This process is repeated until the loss converges to a minimum value or until a specified number of iterations is reached.
For the cross-entropy loss, the gradient with respect to the weights and bias can be derived based on the specific activation function used. The general update rules in gradient descent are:
Where is the learning rate, a hyperparameter that determines the step size of each iteration. By iterating this update rule, the algorithm adjusts the weights and biases to minimize the cross-entropy loss and improves the model's performance on the training data.
Types of Gradient Descent
Batch Gradient Descent (BGD)
- Description: In BGD, the gradient is calculated using the entire training dataset. This means that for each iteration, we use all the training examples to compute the gradient of the loss function.
- Update Rule:
- Advantages:
- Stable convergence.
- Straightforward implementation.
- Disadvantages:
- Can be very slow for large datasets as it processes all training examples for each iteration.
- Requires the entire dataset to be in memory.
Stochastic Gradient Descent (SGD)
- Description: Instead of using the entire dataset, SGD updates the weights using only a single training example at a time.
- Update Rule:
- Advantages:
- Faster than BGD, especially for large datasets.
- Can escape local minima due to its noisy updates.
- Disadvantages:
- Can lead to oscillations in convergence due to the noisy updates.
- Less stable convergence compared to BGD.
Mini-Batch Gradient Descent (MBGD)
- Description: A compromise between BGD and SGD. It updates the weights using a small random subset (mini-batch) of the training dataset. The size of the mini-batch is typically between 10 and 1000.
- Update Rule:
- Advantages:
- Can be faster than both BGD and SGD, especially for large datasets.
- Benefits from both the stability of BGD and the faster convergence of SGD.
- Can be implemented efficiently on parallel hardware (like GPUs).
- Disadvantages:
- Convergence is less stable than BGD but more stable than pure SGD.
MBGD is the most used variant. The choice of batch-size and learning rate are hyperparameters that influence speed and stability of convergence.
Activation Functions
In the case of our single-layer classifier, our activation function was the sign function. And this makes sense, given that a binary class label needs to be predicted. However, there are many different types of situations where different target variables need to be predicted.
If we want to predict a continuous value, we would need a different activation function, such as an identity activation function. The resulting neural network would just be a linear regression model. If we want to predict a probability, we would need a sigmoid activation function. If we want to predict a class label, we would need a softmax activation function. For different situations, there are different activation functions. This is crucial when considering multi-layered neural networks. If a network only used linear activations, then it would be the same as using a simple linear regression model.
The greek letter denotes an activation function:
Technically, a neuron calculates two functions. First, the linear function value is calculated. Then, the activation function is applied to the result of the linear function. The resulting values are called the pre-activation and post-activation values, respectively.
| Activation Function | Equation | Range |
|---|---|---|
| Identity | ||
| Sigmoid | ||
| Tanh | ||
| Rectified Linear Unit (ReLU) | ||
| Hard Tanh | ||
| Softmax |
ReLU is used most widely used for the advantages it offers:
- More computationally efficient (no exponentials)
- Has a gradient of either (for negative values) or (for positive values), which helps mitigate the vanishing gradient problem
- Inherently introduces sparsity (many neurons will have a value of ), which can reduce overfitting
ReLU does have the "dying ReLU" problem. This refers to the problem where neurons in a network can sometimes output a constant zero value for all inputs — essentially becoming inactive and no longer updating during training. This can be mitigated by using leaky ReLU, where is a small constant (, , etc.):
Softmax
There is a bit more to say about softmax. If we would like to classify an input among classes, it becomes a multi-class classification problem. In this case, output values can be used, such that the activation function for the th output node is:
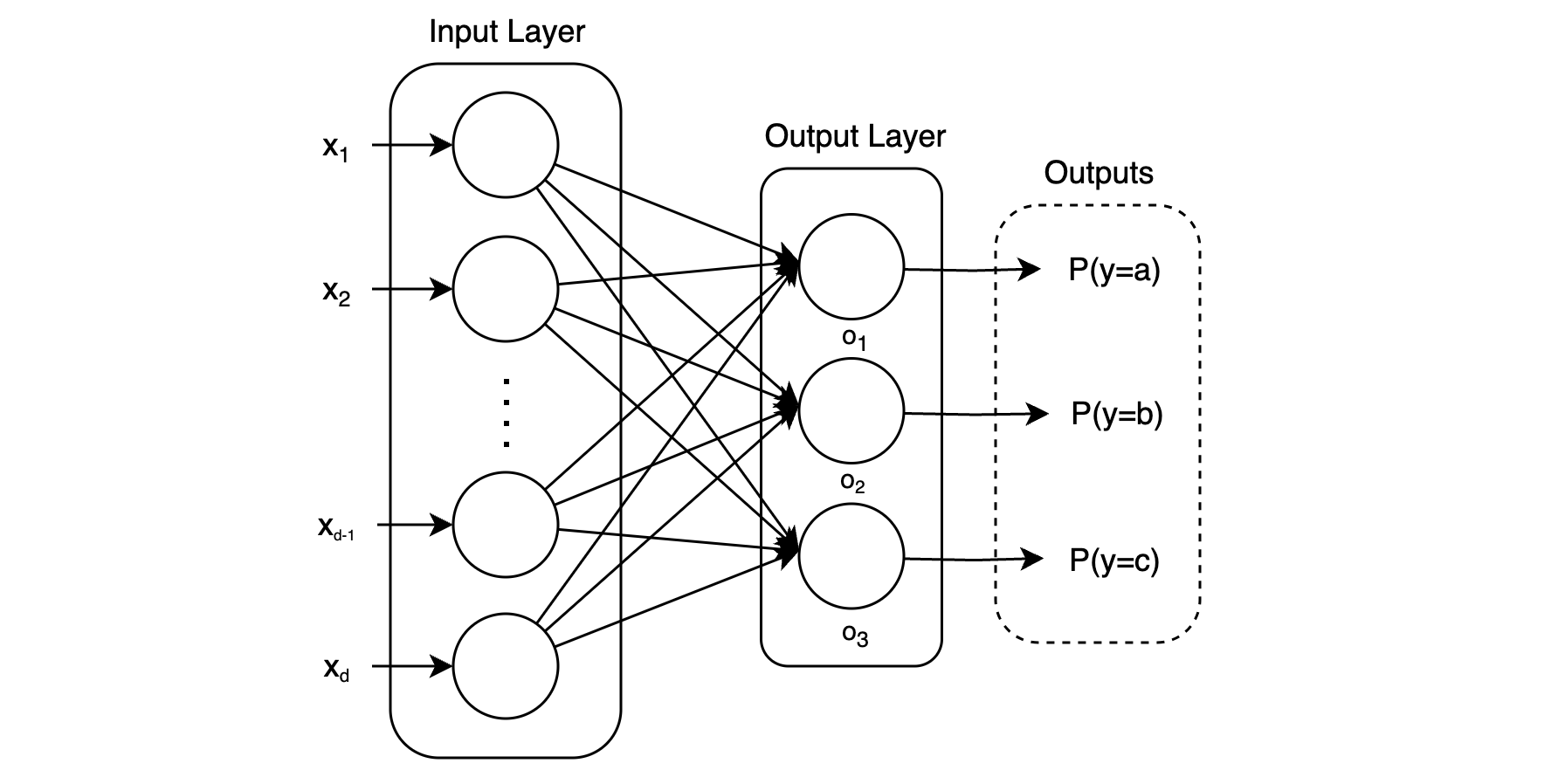
The softmax function is used to normalize the output values to be between and , representing the probability of each class given the input.